


Keep making noodles…



Often, when working on data projects, I come across useful quick snippets of code that help with the Herculean task of sourcing data. I have quite an elaborate scheme of organizing a library of resources in my Dropbox folders. Here is one I recently discovered and have put to immediate use.
In the last two posts I relied on df.info() to explore a few datasets. A lot of times you just want to hop in and hop out but there are occasions where you need a bigger lens to look at big data. Here is where Pandas Profiling is superb. Read the article below for more details but I am pulling the most relevant steps into the blog for your review and direct application to healthcare datasets.
I am a huge fan of Toward Data Science. I try to simplify the most relevant articles for my network over on LinkedIn hoping to encourage the data curious to roll up their sleeves. I found this gem after a day of exploring datasets to help a few clients answer questions formulated around population health.
10 Simple hacks to speed up your Data Analysis in Python

I had to revise some of the code from the article to make it work for me. I tend to use Jupyter notebooks and running commands from the shell ! work better for some reason. This is the code I ran instead of the installation code from the article.

Now we need to import the necessary packages — pandas allows you to convert your tabular into data frames. The link in red is a file I imported from my dropbox files of data sources. To grab the link from your dropbox file simply copy the link provided when you click “share” — replace the “0” with the “1” you see in the file URL below.
I do a lot of work evaluating population health data. This sample is from Community Health Status Indicators (CHSI) — a bit dated but a good practice dataset to experiment with and learn a few new data skills. I have an extensive checklist of curated data sources shared with workshop attendees or clients but I am happy to share an edited sample with anyone — reach out to me either on twitter or LinkedIn.

When you are evaluating datasets, the ability to have an overview of number of variables, missing data, and the types of variables is quite handy. You can also review a list of variables highly correlated with each other and therefore eliminated from comparison. All of the visuals are loaded with the simple code above. I broke it into segments for the purpose of our conversation but the html link will take you to the full output.

Certain data questions won’t require all of the variables in a particular table. Each variable is summarized here and provides useful information on how the variables were coded (categorical for example), distinct counts and missing data are also provided as well as a graphic where warranted. My best practice is usually to review in Python (or R) and use Tableau Prep to remove unwanted columns. More on that in future post.

One more option to view your data dynamically instead of simply in a static readout is using the code below. The # is commented out information and will not interfere with your code.
The x-axis below is the total number of data points while the Y axis is the value of every feature for that particular data point. Hit play to see interactivity.
Obviously a curated dataset is much less crowded but you can select variables for comparison using tools in upper right menu.
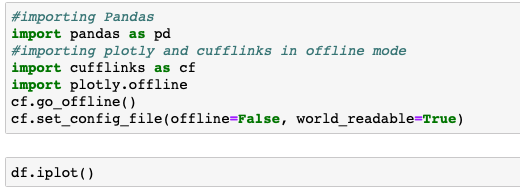
Here is an example of the interactive output.
<a href="https://medium.com/media/b4fba46dfa036f8d77318db0bbb6dc56/href">https://medium.com/media/b4fba46dfa036f8d77318db0bbb6dc56/href</a>
You can view the original blog post on data & donuts or connect over on twitter Bonny P McClain